Adding a GUI wrapper around Mule 4 secure properties
In an earlier post we discussed Securing your Mule 4 properties and your feedback was great. While most of you liked the approach, others felt it was a little too techie for their DevSecOps teams. The feeling was that: there were too many moving parts and the consensus was for a GUI to wrap the encode and decode details.
To that end, I created a GUI wrapper using TornadoFx. You will still need to download the Mule 4 secure-properties-tool.jar that I linked in my previous article. Also, I posted an Uber Jar (not the car hailing company) to my GitHub project packages. The Uber Jar will need to be run from the same folder where you downloaded the mule jar as is shown in the code snippet below.
# list of files
$ ls
secure-properties-tool.jar
SecureProps-0.0.1.jar
# run the jar
$ java -jar SecureProps-0.0.1.jar
When you run the Uber Jar, the SecureProps EncDec application will start up giving your the opportunity to encode or decode your secrets.
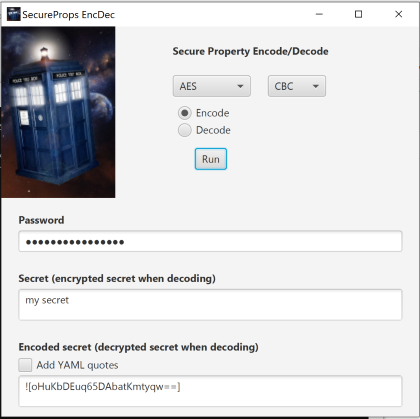
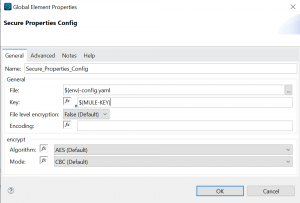
In the Secure Properties GUI select the crypto algorithm and cipher you wish to use. The password is the same mule will use to decode the properties at startup. You’ll add your secret to the secret field and press Run to generate the encoding. The default encoding is for insertion in a .properties file. To produce an encoding for a YAML file be sure to click on the checkbox before hitting the Run button. You can always reverse the process by adding the encoding to the secret field. Just be sure not to include the ![] which wraps the encoding.
Hopefully this will allay the earlier concerns about simplifying the encoding process. In the space that remains i’ll hit some of the high points about TornadoFx and the application.
What is TornadoFx and why is it relevant?
The TornadoFx is a GUI development framework created by Edvin Syse, as a lightweight JavaFx development framework developed in Kotlin.
There’s a lot of info packed into the links above, but probably the main question most people have is: how long will it take to learn a new framework start doing building cool UI’s using TornadoFx? The answer of course is it depends. It depends on whether you’re just starting or have some background in JavaFx, JavaScript, Web development frameworks and the like.
The good news is that TornadoFx extends on the basic concepts of other UI development frameworks, so if you’ve have some prior experience and an understanding of MVC patterns you should be in good shape.
To get you started, you can find the code for the Mule Secure properties app in my GitHub repository. The Uber jar is also there if you would just like to use it for securing your Mule 4 properties. While useful, it’s still an immature version which doesn’t validate any of the parameters you send to the Mule Jar. For example, it will be perfectly happy accepting a password length that’s unacceptable to algorithms like AES which require 16 bytes and you might get results like this: “Invalid AES key length: 8 bytes“. As long as you conform to the happy path it should work fine and acceptable for a non-production grade demo app.
Lets take a look at some code. To run you application, we’ll wrap the JavaFx Stage adds the dimensions for our window, overrides the default application icon with one of our own and passes our MainView class as our view entry point.
class MyApp: App(MainView::class, Styles::class) {
override fun start(stage: Stage) {
with (stage) {
width = 500.0
height = 490.0
}
setStageIcon(Image("images/Favicon.png"))
super.start(stage)
}
}Our MainView and EncDecController fulfills the contractual obligations described by the MVC pattern. Our controller runExec method executes’s the Mule 4 Secure properties config jar, encoding or decoding our secret, using an asynchronous pattern so that our UI view thread doesn’t block. It takes a string as an argument, which we entered manually to the jar when we first reviewed the Mule jar in our last article.
fun runExec(cmd: String) {
val process: Process = Runtime.getRuntime().exec(cmd)
val sc = Scanner(process.inputStream)
conversionRes = SimpleStringProperty(sc.nextLine())
//println(res)
sc.close()
}In the MainView.kt you’ll find most of our UI controls and layout styles. Though, you will probably want to consolidate and centralize most of your layout definitions in a file like the Styles.kt, which is similar in nature to a styles.css. For a better understanding of how Layouts and Controls work in TornadoFx you’ll probably want to review Edvin’s TornadoFx guide. To make you even more productive, Edvin has created a TornadoFx plugin for IntelliJ Idea.
To bootstrap your knowledge even faster you might want to consider taking a Udemy course like Paulo Dichone’s TornadoFx course.
Whether you’re inspired to create your own TornadoFx application or just use one, like this one, I hope you found this an interesting read and that the links help to get you up to speed quickly. As always, I look forward to your feedback and thoughts on improvements.