Moving toward the next generation of ESB’s
The Enterprise Services Bus (ESB) has been around for a while now and we may think of the bus as being a commodity resource. ESB’s are not all the same and some may have improved by the addition of incremental features as well as from lessons learned in the field. Smaller, more nimble vendors, can implement changes at a much faster rate.
In hindsight, when we consider our application integrations, we’re reminded to throw away the first and perhaps the second too. They’re mostly explorations, experiments in understanding the technologies and the business requirements. When we have an improved understanding of the business needs, we can make better informed choices about technology and solutions. There may also be other business reasons to justify moving to the next generation of an ESB, such as:
- Lower Total Cost of Ownership (TCO) due to smaller VM size and lower resource utilization footprint.
- Reduction or elimination of exorbitant license fees.
- New capabilities and features to satisfy your modern Use Cases which weren’t previously available.
With the coming of Internet 2.0 and the Internet of Things (IOT), business will many have new requirements for interacting with: devices, gadgets, smart homes and streams of information in whole new ways. These requirements were never contemplated by earlier generations of ESB designers. To get a better understanding of how the next generation of ESB’s can handle to these requirements, try them out in a small lab like environment as a Proof of Concepts (POC). A POC will allow you experiment with concepts and ideas rapidly, and possibly incubate them into what may become future product sprints.
A next generation ESB i’ve recently dabbled with, which seems to satisfy next generation internet messaging requirements is the Neural Autonomic Transport System (NATS). NATS was created by Derek Collison who was responsible for building and expanding TIBCO’s primary messaging platform. TIBCO invented the concept of the ESB and created the phenomena of realtime event driven enterprise messaging. It’s from Derek’s lessons learned about what a next generation ESB platform should be, that led to the inception of NATS. NATS is maintained under the governance model of the Cloud Native Computing Foundation (CNCF) and is licensed by Apache License v2.0.
In the sections which follow we’ll stand up a nats-server instance and interact with it using a client interface. There’s a wide range of CPU’s and platforms including Docker and Kubernetes, which are supported by the NATS Server, and a growing list of plugin connectors. The NATS documentation is among the best that i’ve seen for an Open Source project.
Without further ado, lets get started with some basic installs on some Raspberry Pi’s and a Windows 10 laptop to get a sense for the ease of installing and configuring the ESB. In future posts we can delve a bit deeper to better understand the richer feature sets.
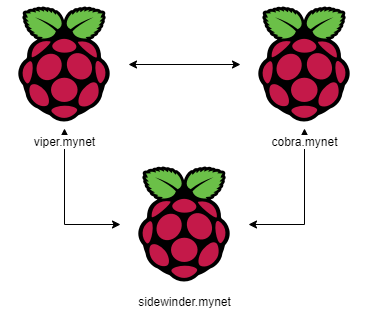
Raspberry Pi 4 lab
In my home mad scientist’s laboratory i’ll be using some combination of the Raspberry’s shown here and for good measure will add in a Windows 10 laptop as well to review a deployment in a Docker container.
The Pi 4 is an ARM 7 CPU and will require the following download. We’ll create a bin directory for the nats-server that we’ll link to from a folder in our HOME directory which we’ll unzip the downloaded server archive into. If you don’t already have a $HOME/bin and $HOME/Install folder lets go ahead and create them.
Install nats-server on Raspberry Pi 4
# Create install and bin folders if needed
viper: $ cd $HOME && mkdir bin Install
# Download and install nats-server
viper: $ wget https://github.com/nats-io/nats-server/releases/download/v2.1.7/nats-server-v2.1.7-linux-arm7.zip
viper: $ cd $HOME/Install
viper: $ unzip $HOME/Downloads/nats-server-v2.1.7-linux-arm7.zip
# link to the server from your bin folder, add bin for your path
viper: $ cd $HOME/bin && ln -s $HOME/Install/nats-server-v2.1.7-linux-arm7
viper: $ export $PATH=$PATH:$HOME/bin
If you wish to keep the nats-server on your path the next time you login, add the export command above to your .bashrc file. Go ahead and repeat the commands above for any additional Pi 4’s or other targets you would like to install the nats-server on. If you’re installing to a PiZero, be sure to use the ARM6 release. The size of the installed nats-server (at the time of this writing) is a little less than 8Mb, which is pretty amazing when you consider the size of other ESB’s.
With the nats-server installed, lets play with some simple messaging API’s to get a sense for how easy it is to do simple things. As is the case with most experiments, well start with the easy things first and add complexity in layers to fit our business needs. As I mentioned earlier, the nats-server documentation is excellent and I recommend your going through it for a better, more thorough understanding of it’s capabilities. We’re going to play with some of that here, but the nitty grtty details are in the docs.
One of the aspects I’ve liked about TIBCO Rendezvous ESB was the simplicity and ease with which you could start a server and exchange subject based messages. These notions of simplicity have carried through into the nats-server.
With subject based messaging we begin by creating an ontology of subjects of interest which best captures our business domains. This concept may be best illustrated with an example.
Example subject namespace
# messages for accounting
ACCOUNTS.BILLABLE.CUSTOMERS
ACCOUNTS.BILLABLE.PARTNERS
ACCOUNTS.PAYABLE.CUSTOMERS
ACCOUNTS.PAYABLE.PARTNERS
MARKETING.CAMPAIGN.CREATE
MARKETING.CAMPAIGN.STATS
PRODUCT.INVENTORY.ITEM.WIDGET.PRICE
PRODUCT.INVENTORY.ITEM.WIDGET.QUANTITY
PRODUCT.INVENTORY.RELOAD
With an ontology of subjects created for our namepace, API’s can express an interest in Publishing to or Subscribing from subjects of interest. Our services can have different qualities assigned depending on the needs of the business. Applications and application users can have differing views of the information by configuring Multi Tenancy into your Accounts.
Lets go ahead and exercise the nats-server we installed earlier with some pub/sub messaging. I’m going to use the Go examples, but you an follow with with an API example that you’re more familiar with. By default, the nats-server can be run with minimal configuration. To be more adaptable to business use cases, you’ll eventually get around to the server configuration file and the command line options. For now, we’ll keep it simple and stick with the default settings. The server runs by default on port 4222.
You’ll need at least 3 shell sessions for the examples, or you can use tmux. We’ll get started by downloading some sample Go client applications, other clients here.
Playing with Pub/Sub
# Download sample client applications using Go
cobra: $ go get github.com/nats-io/nats.go/
# another host
sidewinder: $ go get github.com/nats-io/nats.go/
# start the server on host viper
viper: $ nats-server
[4679] 2020/07/26 15:49:25.319558 [INF] Starting nats-server version 2.1.7
[4679] 2020/07/26 15:49:25.320177 [INF] Git commit [bf0930e]
[4679] 2020/07/26 15:49:25.320765 [INF] Listening for client connections on 0.0.0.0:4222
[4679] 2020/07/26 15:49:25.320832 [INF] Server id is NBMPCVRJHIJ66PFDW5ZS6IVG3W7CGNQV53YIT399243FVWUF5LD7RUJI7PUF
[4679] 2020/07/26 15:49:25.320864 [INF] Server is ready
With the server running on default port 4222, we can send some messages. Messages will be sent as a serialized byte array, commonly they’ll be marshalled from XML or JSON. The examples here will be plaintext. We start by registering a Subscriber on subject lotto.winner.notify and a Publisher will send a message on that same subject.
Send a client message to the nats-server
# subscribe to a subject of interest using example nats client
sidewinder: $ cd $GOPATH/src/github.com/nats-io/nats.go/examples/nats-sub
sidewinder: $ go run main.go -s viper lotto.winner.notify
Listening on [lotto.winner.notify]
# publish a message on subject - lotto.winner.notify
cobra: $ go run main.go -s viper lotto.winner.notify "Congratulations, you won!"
Published [lotto.winner.notify] : 'Congratulations, you won!'
After you Publish the message you should see it arrive in the Subscriber terminal window. Kill the nats-server by sending a SIGTERM, ^C then restart the server with verbose tracing enabled.
# Kill and restart server with verbose tracing
viper: $ ^C
viper: $ nats-server -V
# In the Subscriber terminal watch the disconnect/reconnect
[#1] Received on [lotto.winner.notify]: 'Congratulations, you won!'
Disconnected due to:EOF, will attempt reconnects for 10m
Reconnected [nats://viper:4222]
# In the server observe some ping/ponging
[6537] 2020/07/26 16:07:31.335145 [INF] Starting nats-server version 2.1.7
[6537] 2020/07/26 16:07:31.335927 [INF] Git commit [bf0930e]
[6537] 2020/07/26 16:07:31.336783 [INF] Listening for client connections on 0.0.0.0:4222
[6537] 2020/07/26 16:07:31.336901 [INF] Server id is NA4GNP7LFABC2EUPPSHZEXNEARDUBU5CYKJHEJM77QDH4ZQNG3JWWVGZ
[6537] 2020/07/26 16:07:31.337020 [INF] Server is ready
[6537] 2020/07/26 16:07:31.572089 [TRC] 192.168.1.205:36372 - cid:1 - <<- [CONNECT {"verbose":false,"pedantic":false,"tls_required":false,"name":"NATS Sample Subscriber","lang":"go","version":"1.11.0","protocol":1,"echo":true,"headers":false,"no_responders":false}]
[6537] 2020/07/26 16:07:31.572609 [TRC] 192.168.1.205:36372 - cid:1 - <<- [PING]
[6537] 2020/07/26 16:07:31.572699 [TRC] 192.168.1.205:36372 - cid:1 - ->> [PONG]
[6537] 2020/07/26 16:07:31.575856 [TRC] 192.168.1.205:36372 - cid:1 - <<- [SUB lotto.winner.notify 1]
[6537] 2020/07/26 16:07:31.576197 [TRC] 192.168.1.205:36372 - cid:1 - <<- [PING]
[6537] 2020/07/26 16:07:31.576248 [TRC] 192.168.1.205:36372 - cid:1 - ->> [PONG]
[6537] 2020/07/26 16:07:33.623230 [TRC] 192.168.1.205:36372 - cid:1 - ->> [PING]
[6537] 2020/07/26 16:07:33.626727 [TRC] 192.168.1.205:36372 - cid:1 - <<- [PONG]
There’s a liveness check which goes on between client and server. When the server terminates a client will attempt to reconnect for a predetermined amount of time. A failover strategy allows clients to reattach to another server. Client failures can be handled with strategies as well.
As a final exploration, lets pull the Docker image for the nats-server to a Windows 10 laptop and repeat our pub/sub exercise.
Run the nats-server Docker image
# fetch the nats-server docker image
C:\> docker pull nats
Using default tag: latest
latest: Pulling from library/nats
b509577c0426: Pull complete
61ce65065eb7: Pull complete
Digest: sha256:85589e53092232c686097acfdc3828ac0e20a562d63c5d0f0e7dfceade6fad49
Status: Downloaded newer image for nats:latest
docker.io/library/nats:latest
# Run the Docker container
C:\> docker run --name nats --rm -p 4222:4222 -p 8222:8222 nats
[1] 2020/07/21 06:04:32.534975 [INF] Starting nats-server version 2.1.7
[1] 2020/07/21 06:04:32.534993 [INF] Git commit [bf0930e]
[1] 2020/07/21 06:04:32.535126 [INF] Starting http monitor on 0.0.0.0:8222
[1] 2020/07/21 06:04:32.535157 [INF] Listening for client connections on 0.0.0.0:4222
[1] 2020/07/21 06:04:32.535161 [INF] Server id is NBJ3ACZPYQJE6M4I6KBF4DZSKQMDAI4T6DUOK3JNQ6V4GOVDIZ4G46EH
[1] 2020/07/21 06:04:32.535162 [INF] Server is ready
[1] 2020/07/21 06:04:32.535297 [INF] Listening for route connections on 0.0.0.0:6222
Notice that the container instance exposes the Client port, and HTTP monitor port listening on localhost:8222 and a Route Connections port. Go ahead and view localhost:8222/ in your browser.
Running pub/sub example using Windows 10 Docker Container
# Create subscriber from a target host
sidewinder: $ go run main.go -s 192.168.1.123 lotto.winner.notify
Listening on [lotto.winner.notify]
# Publish a message to the Docker container
cobra: $ go run main.go -s 192.168.1.194 lotto.winner.notify "Congratulations, you won!"
# Verify the message is delivered to the subscriber
[#1] Received on [lotto.winner.notify]: 'Congratulations, you won!'
In a short couple of experiments we explored some basic pub/sub using a standalone and a containerized NATS server. In future posts we may investigate Multi Tenant Accounts, Mutual TLS and Kubernetes solutions. As always keep your questions and comments coming.