A deeper look into using the Beego framework in Go for persisting stateful data
In a recent post we discussed the merits of using the Beego framework in Go to create Web and API projects. We went on to create a sample Web and API project using the CLI. The projects were simple to implement and came with a rich set of features including swagger documentation and built-in monitoring. Many of you were left wondering about the next steps, of adding a persistent set of new API’s to the framework set up by the CLI. That task will be the subject of this article.
To implement the API persistence layer we’ll be using a Postgres database. Beego also supports MySQL and SqLite. If you prefer to use these it should be simple enough to do so following the Beego ORM documentation. I’ve only tested with Postgres, other databases may require some addition tweaking on your part. To create a new Postgres instance you can refer to my instructions in Better practices for Go Databases.
With the caveats behind us, lets roll up our sleeves and get going!
Completed code in Github, branch wine-db.
Here’s what the completed project should look like, with a review of the changes from the default created with the CLI.
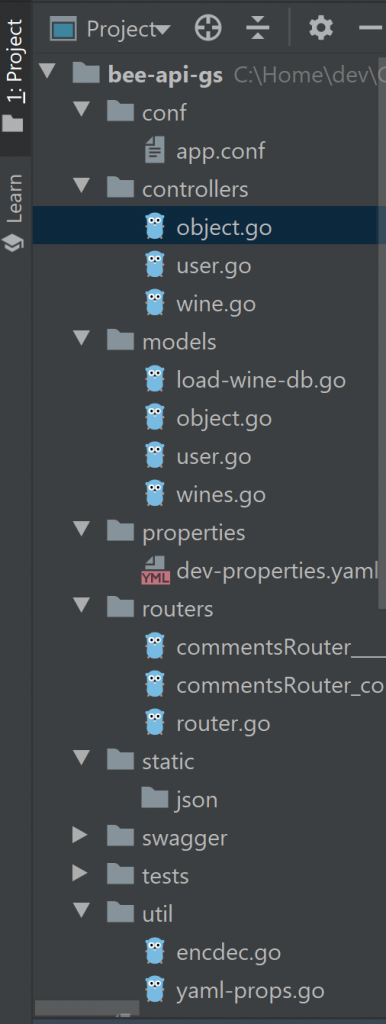
We’ve incorporated the YAML property file and encrypted properties which we created earlier in Better practices for Go Databases. To decode the secrets you’ll need to set or pass the secret environment variable as described in the article.
Also note that we’ve included new controller and models files wine.go. The router.go has been modified to support the new API route and main.go has been modified to support encrypted YAML properties and connection to Postgres.
I had hoped to use more of the raw primitives we used in the better practices article, but frameworks typically have their own ways of doing things and I was overcome by my curiosity to learn how to apply the Beego ORM framework. As we’ve already looked at the properties and utilities in the better practices article, we won’t repeat that again here.
Getting things started in main.go.
package main
import (
"github.com/astaxie/beego/orm"
"github.com/mjd/bee-api-gs/models"
_ "github.com/mjd/bee-api-gs/routers"
"github.com/mjd/bee-api-gs/util"
"log"
"github.com/astaxie/beego"
_ "github.com/lib/pq"
)
// init behaves like an object constructor
func init () {
// 1 - Enable debug
orm.Debug = false
// 2 - Register object with Beego ORM
orm.RegisterModel(new(models.Wine))
// 3 - Fetch database properties stored as YAML, decode secrets
connStr, err := util.FetchYAML()
if err != nil {
log.Fatalf("error: %v", err)
}
// 4 - Register posgres driver and db
orm.RegisterDriver("postgres", orm.DRPostgres)
orm.RegisterDataBase("default", "postgres", connStr)
// 5 - Create and load DB with sample data, can comment after initial load
models.CreateDb()
models.LoadDb()
}
func main() {
// Load Beego framework
if beego.BConfig.RunMode == "dev" {
beego.BConfig.WebConfig.DirectoryIndex = true
beego.BConfig.WebConfig.StaticDir["/swagger"] = "swagger"
}
beego.Run()
}
The main function remains untouched from what the CLI provided us. You’ll note the addition of init, which gets invoked by Go prior to any func’s being executed. The comments should give a good idea of what’s goin on in init().
- Enable debug, change to true for ORM debug
- Register Wine object with Beego ORM
- Fetch the database properties stored as YAML, decode secrets
- Register posgres driver and db
- Create and load DB with sample data, can comment after initial load
Router changes
func init() {
ns := beego.NewNamespace("/v1",
beego.NSNamespace("/object",
beego.NSInclude(
&controllers.ObjectController{},
),
),
beego.NSNamespace("/user",
beego.NSInclude(
&controllers.UserController{},
),
),
// New route for Wine API
beego.NSNamespace("/wine",
beego.NSInclude(
&controllers.WineController{},
),
),
)
beego.AddNamespace(ns)
}In router.go we added a new route to support CRUD operations for the Wine API, otherwise the other routes are the defaults provided by the CLI. In future articles i’ll be stripping out the artifacts which aren’t needed, but for now we’re just getting started and relate to the earlier work.
Create and Load static data with load-wine-db.go
package models
import (
"fmt"
"github.com/astaxie/beego/orm"
)
// Uses Beego ORM to create table
func CreateDb() error {
// Database alias.
name := "default"
// Drop table and re-create (change to false after created).
force := true
// Print log.
verbose := true
// Beego ORM function to create the table
err := orm.RunSyncdb(name, force, verbose)
if err != nil {
fmt.Println(err)
return err
}
return nil
}
func LoadDb() error {
// Some sample data to add to our DB
wines := []Wine{
{
Product: "SOMMELIER SELECT",
Description: "Old vine Cabernet Sauvignon",
Price: 159.99,
},
{
Product: "MASTER VINTNER",
Description: "Pinot Noir captures luscious aromas",
Price: 89.99,
},
{
Product: "WINEMAKER'S RESERVE",
Description: "Merlot featuring complex flavors of cherry",
Price: 84.99,
},
{
Product: "ITALIAN SANGIOVESE",
Description: "Sangiovese grape is famous for its dry, bright cherry character",
Price: 147.99,
},
}
// Insert static entries into database
for idx := 0; idx < len(wines); idx++ {
w := wines[idx]
_, err := AddWine(w)
if err != nil {
return err
}
}
return nil
}
CreateDB uses Beego’s orm.RunSyncdb to create the Wine table, additional information is provided in the Generate Tables section of the doc. LoadDb inserts some sample rows into the Wine table.
Controller for wine.go CRUD operations
package controllers
import (
"encoding/json"
"github.com/astaxie/beego"
"github.com/mjd/bee-api-gs/models"
"strconv"
)
// Operations about Wine
type WineController struct {
beego.Controller
}
// @Title CreateWine
// @Description Add a new wine
// @Param body body models.Wine true "body for user content"
// @Success 200 {int} models.Wine.Id
// @Failure 403 body is empty
// @router / [post]
func (u *WineController) Post() {
var wine models.Wine
json.Unmarshal(u.Ctx.Input.RequestBody, &wine)
uu, err := models.AddWine(wine)
if err != nil {
// handle error
u.Data["json"] = err.Error()
} else {
u.Data["json"] = uu
}
u.ServeJSON()
}
// @Title GetAll
// @Description get all Wines
// @Success 200 {object} models.Wine
// @router / [get]
func (u *WineController) GetAllWines() {
wines, err := models.GetAllWines()
if err != nil {
}
u.Data["json"] = wines
u.ServeJSON()
}
// @Title Get
// @Description get wine by uid
// @Param uid path string true "The key for staticblock"
// @Success 200 {object} models.Wine
// @Failure 403 :uid is empty
// @router /:uid [get]
func (u *WineController) Get() {
uid := u.GetString(":uid")
if uid != "" {
i, err := strconv.Atoi(uid)
if err != nil {
u.Data["json"] = err.Error()
} else {
wine, err := models.GetWine(i)
if err != nil {
u.Data["json"] = err.Error()
} else {
u.Data["json"] = wine
}
}
}
u.ServeJSON()
}
// @Title Update
// @Description update the wine
// @Param uid path string true "The uid you want to update"
// @Param body body models.Wine true "body for user content"
// @Success 200 {object} models.Wine
// @Failure 403 :uid is not int
// @router /:uid [put]
func (u *WineController) Put() {
uid := u.GetString(":uid")
if uid != "" {
var wine models.Wine
json.Unmarshal(u.Ctx.Input.RequestBody, &wine)
uu, err := models.UpdateWine(uid, wine)
if err != nil {
u.Data["json"] = err.Error()
} else {
u.Data["json"] = uu
}
}
u.ServeJSON()
}
// @Title Delete
// @Description delete the wine
// @Param uid path string true "The uid you want to delete"
// @Success 200 {string} delete success!
// @Failure 403 uid is empty
// @router /:uid [delete]
func (u *WineController) Delete() {
uid := u.GetString(":uid")
i, err := strconv.Atoi(uid)
if err != nil {
u.Data["json"] = err.Error()
} else {
models.DeleteWine(i)
u.Data["json"] = "delete success!"
u.ServeJSON()
}
}
The wine controller is invoked by the router when it finds /v1/wine in the URI. Each operation is commented so we an generate Swagger documentation for our API specification. Otherwise the code is fairly simple and straight forward. Each function invokes an operation on the Wine model to perform the CRUD operation. The JSON results are returned to the client.
The Wine model
package models
import (
"github.com/astaxie/beego/orm"
"strconv"
"time"
)
// Marshal Wine model to ORM
type Wine struct {
Id int `orm:"auto"`
Product string `orm:"size(64)"`
Description string `orm:"size(128)"`
Price float32 `orm:"null"`
CreatedAt time.Time `orm:"auto_now_add;type(datetime)"`
UpdatedAt time.Time `orm:"auto_now;type(datetime);null"`
}
func GetAllWines() ([]*Wine, error) {
o := orm.NewOrm()
var wines []*Wine
qs := o.QueryTable("wine")
_, err := qs.OrderBy("Id").All(&wines)
if err != nil {
return nil, err
}
return wines, nil
}
func GetWine(id int) (*Wine, error) {
o := orm.NewOrm()
// Fetch wine by Id
wine := Wine{Id: id}
err := o.Read(&wine)
if err != nil {
return nil, err
}
return &wine, nil
}
func AddWine(wine Wine) (*Wine, error) {
o := orm.NewOrm()
id, err := o.Insert(&wine)
if err != nil {
return nil, err
}
return GetWine(int(id))
}
func UpdateWine(uid string, wine Wine) (*Wine, error) {
o := orm.NewOrm()
// Assign Id to update
id, err := strconv.Atoi(uid)
if err != nil {
return nil, err
}
wine.Id = id
var fields []string
// Update changed fields
if wine.Description != "" {
fields = append(fields, "Description")
}
if wine.Product != "" {
fields = append(fields, "Product")
}
if wine.Price != 0.0 {
fields = append(fields, "Price")
}
_, err = o.Update(&wine, fields...)
if err != nil {
return nil, err
}
// Return JSON for update
return GetWine(id)
}
func DeleteWine(id int) (*Wine, error) {
// wine := new(Wine)
o := orm.NewOrm()
// Select the object to delete
wine := Wine{Id: id}
err := o.Read(&wine)
if err != nil {
return nil, err
}
// delete
_, err = o.Delete(&wine)
return &wine, nil
}The Wine struct uses ORM hints to prescribe operations or features to be be applied to our database columns, details can be found in the Set parameters section of the Beego doc.
- GetAllWines – returns all rows orderd by Id
- GetWine -return wine for the Id passed in
- UpdateWine – creates a slice of changes, passed to Update as a variadic parameter
- DeleteWine – completed the CRUD lifecycle
On to the fun part, sending some JSON messages and see what comes back!
We’ll be using HttpIe in our examples, but if you prefer curl please see the Swagger doc references.
# set the secret
$ export secret='aaaaBBBB1234&^%$'
# run beego app
$ bee run -downdoc=true -gendoc=true
# find swagger apidoc here: http://127.0.0.1:8080/swagger/Get all rows
$ http :8080/v1/wine
HTTP/1.1 200 OK
Content-Length: 954
Content-Type: application/json; charset=utf-8
Date: Fri, 19 Jun 2020 21:12:46 GMT
Server: beegoServer:1.12.1
[
{
"CreatedAt": "2020-06-19T21:06:44.691086Z",
"Description": "Old vine Cabernet Sauvignon",
"Id": 1,
"Price": 159.99,
"Product": "SOMMELIER SELECT",
"UpdatedAt": "2020-06-19T21:06:44.691086Z"
},
{
"CreatedAt": "2020-06-19T21:06:44.695087Z",
"Description": "Pinot Noir captures luscious aromas",
"Id": 2,
"Price": 89.99,
"Product": "MASTER VINTNER",
"UpdatedAt": "2020-06-19T21:06:44.695087Z"
},
{
"CreatedAt": "2020-06-19T21:06:44.697086Z",
"Description": "Merlot featuring complex flavors of cherry",
"Id": 3,
"Price": 84.99,
"Product": "WINEMAKER'S RESERVE",
"UpdatedAt": "2020-06-19T21:06:44.697086Z"
},
{
"CreatedAt": "2020-06-19T21:06:44.700086Z",
"Description": "Sangiovese grape is famous for its dry, bright cherry character",
"Id": 4,
"Price": 147.99,
"Product": "ITALIAN SANGIOVESE",
"UpdatedAt": "2020-06-19T21:06:44.701087Z"
}
]Get wine by Id
# wine by Id
$ http :8080/v1/wine/2
HTTP/1.1 200 OK
Content-Length: 210
Content-Type: application/json; charset=utf-8
Date: Fri, 19 Jun 2020 21:13:57 GMT
Server: beegoServer:1.12.1
{
"CreatedAt": "2020-06-19T21:06:44.695087Z",
"Description": "Pinot Noir captures luscious aromas",
"Id": 2,
"Price": 89.99,
"Product": "MASTER VINTNER",
"UpdatedAt": "2020-06-19T21:06:44.695087Z"
}
Add a new wine to the collection
# POST a new wine
$ http POST :8080/v1/wine Price:=42.24 Product="Fat Bastard" Description="Intense, cherry red in color with fruit-forward flavors of crushed strawberry and wild raspberry"
HTTP/1.1 200 OK
Content-Length: 268
Content-Type: application/json; charset=utf-8
Date: Fri, 19 Jun 2020 21:16:42 GMT
Server: beegoServer:1.12.1
{
"CreatedAt": "2020-06-19T21:16:42.141532Z",
"Description": "Intense, cherry red in color with fruit-forward flavors of crushed strawberry and wild raspberry",
"Id": 5,
"Price": 42.24,
"Product": "Fat Bastard",
"UpdatedAt": "2020-06-19T21:16:42.141532Z"
}
Update a row
# PUT an update
$ http PUT :8080/v1/wine/5 Price:=84.48 Product="Fetid Cow"
HTTP/1.1 200 OK
Content-Length: 266
Content-Type: application/json; charset=utf-8
Date: Fri, 19 Jun 2020 21:18:44 GMT
Server: beegoServer:1.12.1
{
"CreatedAt": "2020-06-19T21:16:42.141532Z",
"Description": "Intense, cherry red in color with fruit-forward flavors of crushed strawberry and wild raspberry",
"Id": 5,
"Price": 84.48,
"Product": "Fetid Cow",
"UpdatedAt": "2020-06-19T21:18:44.644836Z"
}Delete a row
# Delete row
$ http DELETE :8080/v1/wine/5
HTTP/1.1 200 OK
Content-Length: 17
Content-Type: application/json; charset=utf-8
Date: Fri, 19 Jun 2020 21:20:04 GMT
Server: beegoServer:1.12.1
"delete success!"In summary
- We refactored our earlier basic CLI API project to include a new API
- Properties, including secrets are stored in YAML
- New API persists data using Beego ORM
- Our API is documented for the world using Swagger
All of this goodness in just a few hours of work, but all this talk of wine has made me thirsty, cheers!